Co-located with the fifteenth biennial Language Resources and Evaluation Conference (LREC), Palma, Mallorca (Spain).
Important information
Room name: Portixol 2. The room is located on the 3rd floor of the Hotel Melià Palma Bay. The hotel is connected to Palau de Congressos de Palma via a bridge corridor.
Poster Session Location: Menorca Hall situated on the 3rd floor of the Palau de Congressos.
Zoom link for registered participants and presenters:
- The link is available ONLY through the CONFlux app.
- Go to the app, open “Schedule”.
- Choose our workshop from the list.
- Select “Private” by changing the tab. If all is successful, you are supposed to end up on the following app page:
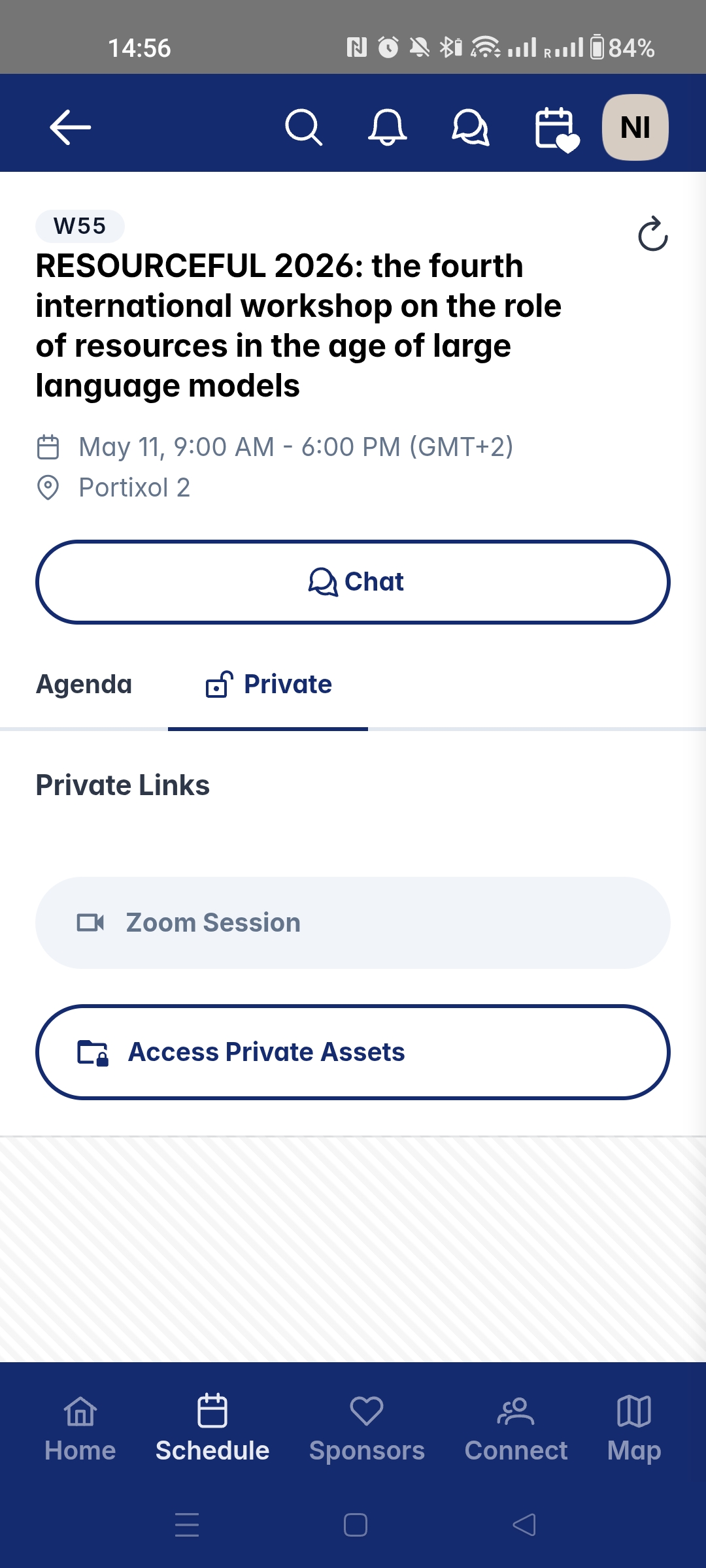
Zoom Session link is then available, it is in grey, but it works. Click on it and join the session.
Proceedings
The proceedings are now available through the LREC 2026 website. The proceedings are expected to be added to the https://lrec.elra.info website in the week of the workshop.
Some lunch options near the conference venue:
- There will be food trucks just outside the conference venue. Lunch boxes will also be available in the Palau de Congressos.
We can issue a certificate of attendance and/or a certificate of presentation for RESOURCEFUL 2026 upon request. If you need one, please email resourceful [at] listserv [dot] gu [dot] se. In your email subject, specify either “RESOURCEFUL 2026 – Certificate of Attendance Request” or “RESOURCEFUL 2026 – Certificate of Presentation Request”. Additionally, include the names of the authors, the title(s) of the paper(s), and the presentation mode in your email. Describe any additional requests in your email. For certificates of attendance or presentation for LREC 2026, please contact the local organisers of LREC 2026.
The proceedings will be published in the ACL Anthology, link will be available soon.
Workshop description
The workshop is a continuation of the workshop series RESOURCEFUL, focusing on the role of resources in the age of large language models (LLMs).
The language resources community has long provided the empirical foundation for language technology, building datasets that have been crucial for development of NLP models. However, the introduction of large language models (LLMs), trained on vast and undisclosed texts, has disrupted this ecosystem. Traditional notions and methods of resource building are evolving. As LLMs have absorbed tons of publicly available data, the boundaries between training and evaluation sets are becoming blurred, and the very idea of “unseen” data is fading. Moreover, these models can now generate synthetic linguistic data, enabling the creation of new linguistic material for the models. This paradigm introduces new challenges and risks, particularly in the domain of evaluation. These shifting dynamics raise fundamental questions about how we evaluate models, ensure data transparency, and preserve the integrity of linguistic resources. The RESOURCEFUL 2026 workshop aims therefore at stimulating a critical dialogue on the methodological, ethical, and practical dimensions of data creation, authenticity, and representation in the age of LLMs.
The workshop aims to bring together researchers involved in the creation, validation, and evaluation of next-generation language resources. We invite contributions from all areas of language resource research, especially on (i) corpus and annotation design, (ii) evaluation and benchmarking methodologies, (iii) low-resource NLP and linguistic diversity, (iv) synthetic data generation and validation, (v) ethics, data governance, and reproducibility. We aim to promote a discussion between traditional resource builders, evaluation specialists, linguists, anthropologists, field researchers and LLM researchers, creating a shared forum to redefine the role of resources in NLP.
Topics of interest
We would like to open a forum by bringing together students, researchers, and experts to address and discuss the following points:
- Novel approaches beyond static datasets; resources as processes; reusable, dynamic, and interactive resources.
- Documentation, reproducibility, and transparency in procedurally generated or evolving resources.
- Limitations and opportunities in using LLMs as ``judges’’ or co-annotators to support expert-based linguistic annotation.
- Quantifying linguistic, pragmatic, cultural dimensions and related biases for resource creation including LLM-generated data.
- Semi-automatic and human-in-the-loop methods for benchmark creation and model evaluation.
- Synthetic and transfer-based methods for low-resource and domain-specific languages.
- Evaluation under data scarcity, domain shift, or limited access to real data or annotators.
- Maintaining and updating benchmarks in the LLM era.
- Methods for generating and benchmarking synthetic linguistic data; incorporation of such data in model training and evaluation.
- Purpose-based, Turing-test inspired or interaction-based evaluation of NLP systems.
- Data ownership, governance, consent, and community-centered perspectives in data creation for under-represented languages.
- Ethical and legal implications of automatically generated data.
- Metadata and documentation practices for evolving and synthetic resources.
- Long-term sustainability and openness of linguistic resources.
Contact
E-mail: resourceful at listserv dot gu dot se